





📜 Paper-List-DAILY
Automatically track & organize the latest arXiv papers by topic — updated daily via GitHub Actions
📅 Last Updated:
2026.07.05· 🤖 Auto-generated by GitHub Actions
📖 Introduction
Paper-List-DAILY is an automated arXiv paper tracking system that fetches, categorizes, and organizes the latest research papers across 20+ computer vision & AI topics — from classic tasks like Object Detection and Segmentation to cutting-edge fields like Diffusion Models, LLMs, and Embodied AI.
Every day, GitHub Actions automatically polls the Papers with Code API, enriches paper metadata with arXiv links, translation services, and code repositories, then generates beautifully formatted Markdown lists for both GitHub README and GitHub Pages.
🌐 Online Documentation: https://isLinXu.github.io/paper-list/
🗺️ Topic Coverage
| Category | Topics | |----------|--------| | **Perception Core** | Classification · Object Detection · Semantic Segmentation · Anomaly Detection | | **3D and Motion** | Object Tracking · Action Recognition · Pose Estimation · Depth Estimation · Optical Flow | | **Foundation Models** | Image Generation · Diffusion Models · LLM · Latent Space LLM · Multimodal | | **Systems Frontier** | Scene Understanding · Video Understanding · Neural Rendering · Transfer Learning · Reinforcement Learning · Graph Neural Networks · Audio Processing | | **Emerging** | AI Agent · Reasoning · World Models · 3D Vision · Autonomous Driving · Robotics · Embodied AI | | **Science & Safety** | AI for Science · AI Safety · Efficient AI · Time Series & Anomaly |✨ Features
| Feature | Description |
|---|---|
| 🔄 Daily Auto-Update | Runs every 8 hours via GitHub Actions — zero manual intervention |
| 📂 20+ Research Topics | From Classification to Embodied AI, covering the full CV/AI spectrum |
| 📊 Research Insights | Trend charts, topic rankings, top authors, and code coverage |
| 🔗 Smart Link Enrichment | Auto-attaches arXiv PDF, translation, reading, alphaXiv discussion, and code links |
| 📱 Dual Output | Generates both GitHub README and Jekyll-powered GitHub Pages |
| 🤖 Dual Reading Modes | Human-facing view + compact ?view=agent mode |
| 🎨 Three Visual Themes | Editorial (warm), Atlas (dark), Lab (clean) — switchable |
| 🔍 Configurable Keywords | Fully customizable search filters via config.yaml |
| 📈 Monthly Archives | Papers organized by month for easy historical browsing |
| 🌐 Multi-language Support | Integrated paper translation links for non-English readers |
🏗️ How It Works
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Papers with │────▶│ GitHub Actions │────▶│ Enriched MD │
│ Code API │ │ (every 8h) │ │ + Analytics │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
▼ ▼ ▼
📥 Fetch Papers 🔗 Enrich Links 📝 Generate
🔍 Filter by Topic 📊 Build Analytics 🌐 GitHub Pages
📅 Sort by Date 💾 Store JSON 📄 README.md
🧭 Reading Paths
| Path | When to use |
|---|---|
| Topic-first | Start from the live site homepage → choose a topic lane → open a monthly archive |
| Dense scan | Open paper_list.html for one continuous all-topics stream with browser search |
| Analytics | Open the insights dashboard for charts, rankings, and code coverage |
| Agent mode | Add ?view=agent on GitHub Pages for a denser, lower-noise reading mode |
🚀 Quick Start
Prerequisites
- Python 3.10+
- pip
Installation
# 1. Clone the repository
git clone https://github.com/isLinXu/paper-list.git
cd paper-list
# 2. Install dependencies
pip install -r requirements.txt
# 3. Run the setup wizard (first time)
python scripts/setup_fork.py
# 4. Dry-run to preview
python get_paper.py --dry-run --start_date 2026-06-01 --end_date 2026-06-08
# 5. Fetch papers
python get_paper.py
# Or specify a date range
python get_paper.py --start_date 2024-01-01 --end_date 2024-12-31
Configuration
Customize search keywords, output paths, and more in config.yaml:
keywords:
"Object Detection":
enabled: true
filters: ["Object Detection", "2D Object Detection", "3D Object Detection"]
"Diffusion Models":
enabled: true
filters: ["Diffusion Model", "Stable Diffusion", "DALL-E"]
🔧 Advanced Usage
| Command | Description |
|---|---|
python get_paper.py --dry-run |
Preview what would be fetched without writing files |
python get_paper.py --topic "Object Detection" |
Fetch a single topic only |
python get_paper.py --update_paper_links |
Enrich existing papers with code links |
python scripts/count_range.py 2024-01-01 2024-12-31 |
Count papers in a date range |
python scripts/build_analytics.py --store docs/data --out docs/analytics |
Build research insights dashboard |
python scripts/filter_audit.py |
Audit filter efficiency (find zombie filters) |
python scripts/validate_config.py |
Validate config.yaml before running |
python scripts/setup_fork.py |
Interactive fork setup wizard |
make dry-run |
Shortcut: preview fetch |
make fetch |
Shortcut: fetch today’s papers |
📚 Paper List
Browse topics by research lane first, then jump into each monthly archive.
- 1Classification
- 2Object Detection
- 3Semantic Segmentation
- 4Anomaly Detection
- 5Object Tracking
- 6Action Recognition
- 7Pose Estimation
- 8Depth Estimation
- 9Optical Flow
- 10Image Generation
- 11Diffusion Models
- 12LLM
- 13Latent Space LLM
- 14Multimodal
- 15Neural Rendering
- 16Reinforcement Learning
- 17Transfer Learning
- 18Audio Processing
- 19Graph Neural Networks
- 20Scene Understanding
- 21Video Understanding
📊 Research Insights
Analytics is available as a separate entrance so the main reading flow stays topic-first.
- Insights Dashboard: analytics/
- Daily Trend: Papers published per day
- Topic Ranking: Most active research areas
- Top Authors: Most prolific researchers
- Code Coverage: Ratio of papers with open-source code
📈 Preview charts
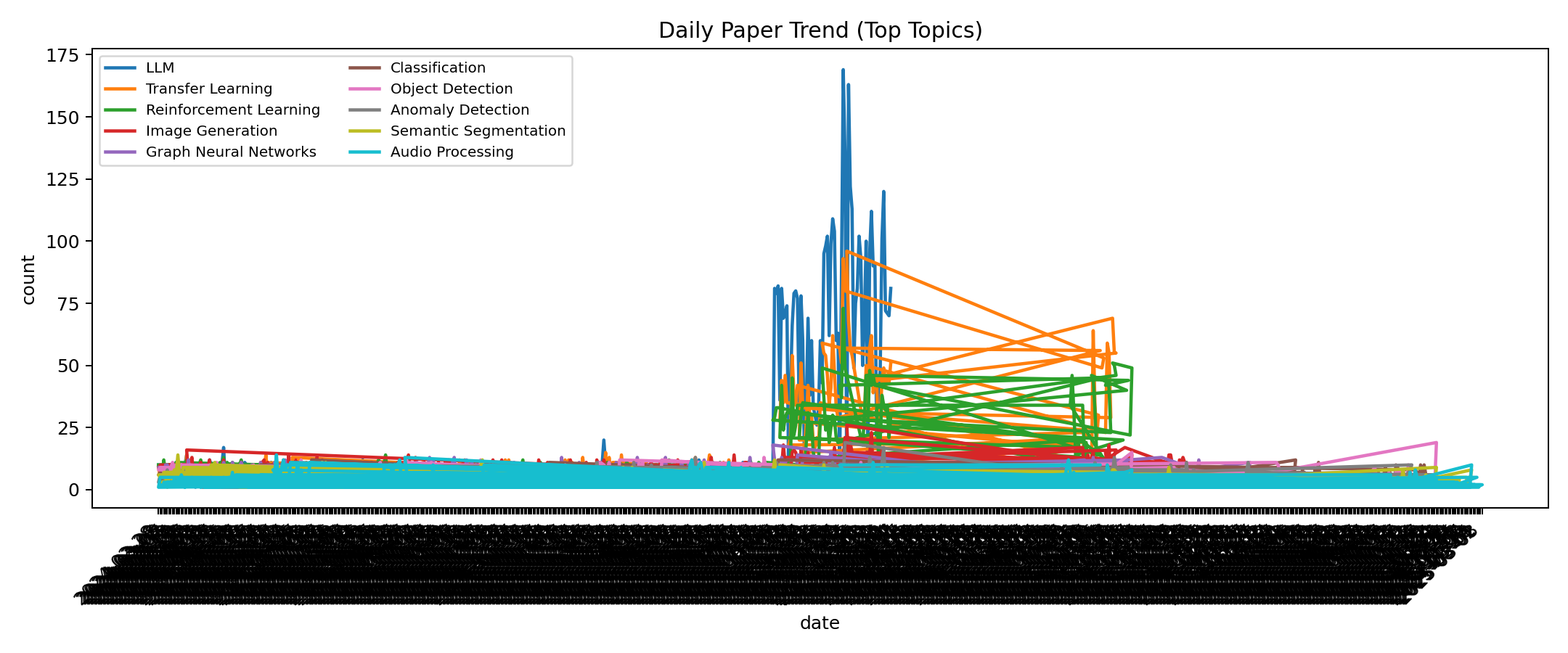 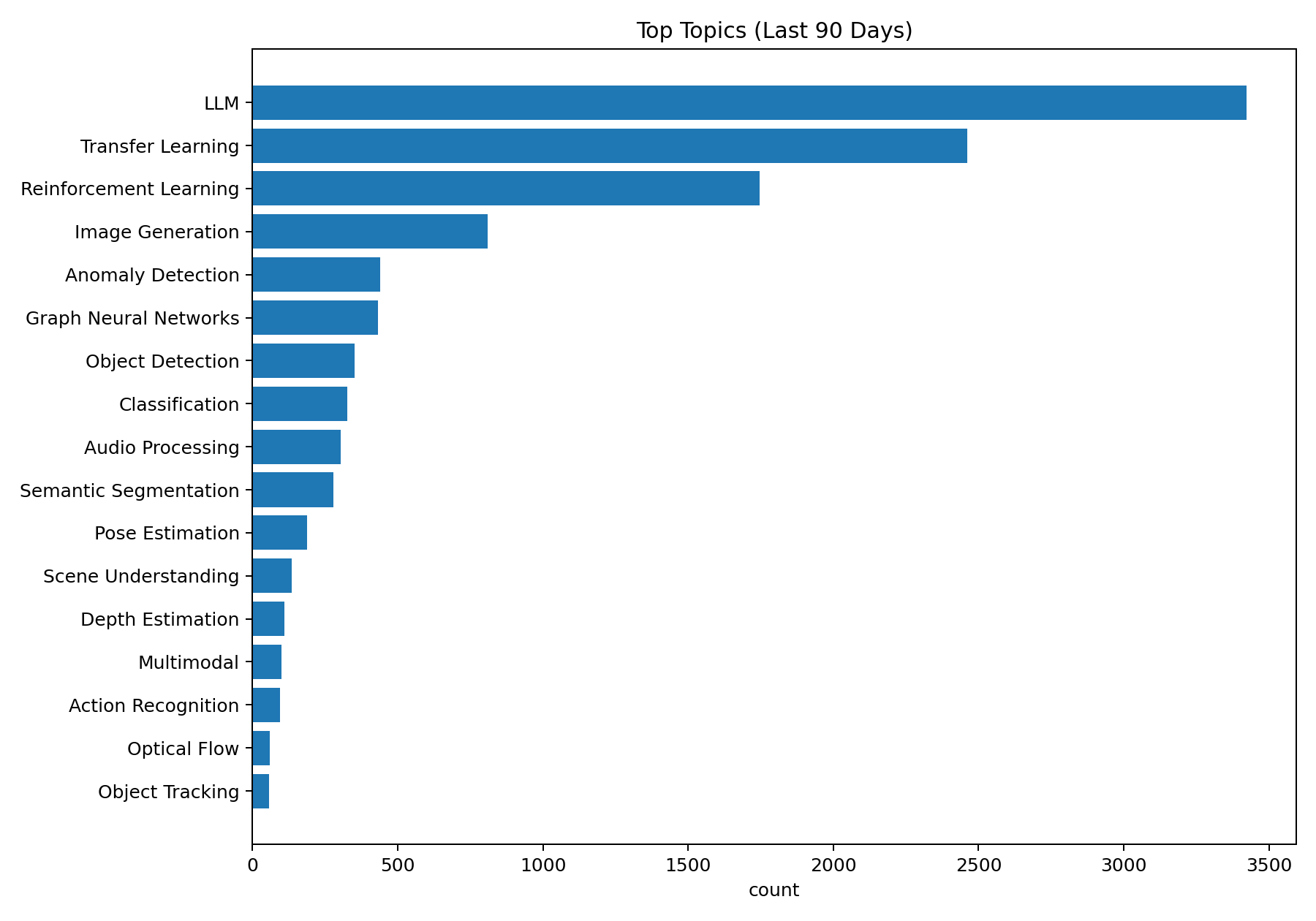⭐ Star History
If you find this project helpful, please consider giving it a ⭐ — it helps others discover the project!
🤝 Contributing
We welcome contributions! Here are some ways you can help:
| Type | How |
|---|---|
| 🐛 Report Issues | Open an issue for bugs or missing papers |
| 💡 Suggest Topics | Propose new research categories in the issues |
| 🔧 Improve Code | Submit a PR to enhance the scraper, analytics, or UI |
| 📖 Improve Docs | Help us write better documentation |
Development Setup
# Fork and clone
git clone https://github.com/isLinXu/paper-list.git
cd paper-list
# Install dependencies
pip install -r requirements.txt
# Run the setup wizard
python scripts/setup_fork.py
# Run tests
python -m pytest tests/
📄 License
This project is licensed under the Apache License 2.0.
The paper data is sourced from arXiv and Papers with Code, and remains subject to their respective terms of use.
🙏 Acknowledgements
| Service | Contribution |
|---|---|
| arXiv | Open access to research papers |
| Papers with Code | Comprehensive paper API |
| papers.cool | Paper translation services |
| hjfy.top | Enhanced paper reading experience |
| alphaXiv | Interactive paper discussion and annotation |
Built with ❤️ by @isLinXu · Powered by GitHub Actions